Quickstart
NVIDIA CCluster provides dedicated LLM endpoints, general inference, and compute deployments — all backed by optimized infrastructure.
No need to worry about GPU provisioning, scaling, or maintenance — just log in and deploy.
1. Log into the NVIDIA CCluster
To get started, sign in to the NVIDIA CCluster console using the access details provided by your NVIDIA team.
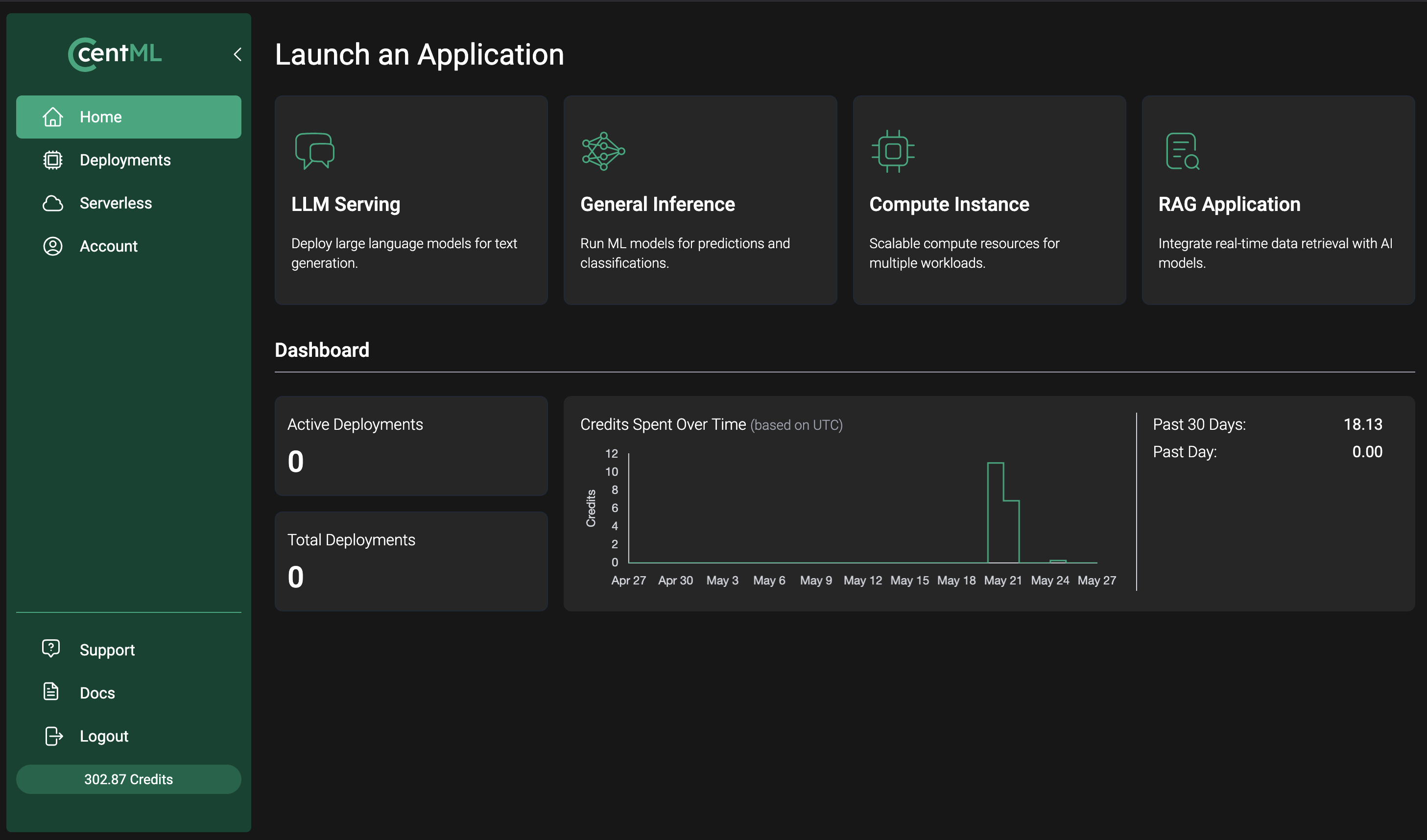
Once logged in, you will see the NVIDIA CCluster console home page, as shown below.
2. Create a bearer token
Endpoints are never public — every request must authenticate with a Bearer token or a client certificate. To interact with NVIDIA CCluster endpoints programmatically, generate a Bearer Token by following the Managing Vault Objects documentation. For all protection options, see Securing Endpoints.
3. Deploy your first model
Choose the deployment type that fits your use case:
- LLM Serving — Deploy dedicated, protected LLM endpoints tailored to your performance requirements and budget.
- General Inference — Deploy custom containerized models on NVIDIA-managed infrastructure.
- Compute — Provision GPU compute for training, fine-tuning, or batch workloads.
Additional support: billing, sales, and/or technical
For access, billing, sales, or technical assistance, follow our Requesting Support guide.