The Problems Teams Face
Standard model operations often require extensive configuration and troubleshooting, leading to increased costs and delays. For users who simply want to interact with a model, this can create a frustrating experience and extend project timelines. As teams scale, the burden of debugging, tuning, and optimization grows. They must continuously evaluate current and future model outputs to meet evolving response quality SLAs—making the process even more time-consuming and labor-intensive.The CentML Solution
CentML serverless endpoints abstract away the need for teams to worry about underlying deployment infrastructure, scaling, or maintenance while they are in the “Feasibility Analysis” phase of their model integration lifecycle (MILC). Teams can simply log in to begin testing and evaluating models, focusing on how well they align with business needs and feasibility objectives such as:- Text Generation Quality: Does the model generate coherent, fluent, and contextually relevant text?
- Task-Specific Performance: How well does the model perform on specific tasks, such as conversational dialogue, summarization, or question-answering?
- Common Sense and World Knowledge: Are there any obvious gaps or inaccuracies in the model’s knowledge or understanding? Is this due to a knowledge cut off date?
- Bias and Stereotyping: Does the model perpetuate or amplify biases and stereotypes present in the training data?
- Adversarial Robustness: How well does the model handle adversarial inputs or attacks, such as those designed to elicit nonsensical or biased responses?
- Explainability and Transparency: Can the model’s outputs or decisions be explained or justified in a way that is understandable to humans?
- Overfitting and Memorization: Does the model rely too heavily on memorization of the training data, rather than generalizing to new or unseen inputs?
Prerequesites
CentML’s Serverless endpoints can be accessed via the chat UI, as well as programmatically using Python, JavaScript, and cURL commands. Before attempting to access the CentML’s serverless endpoints, please make sure you’ve followed the Quickstart guide in order to create an account and an API token as well as access the Chat UI.Accessing the Chat UI
As a refresher from the Quickstart guide, in order to access the chat UI, you must select theServerless option from the sidebar menu.
Configuring the Endpoint
The configuration menu, located on the right side of theYour Serverless Endpoints screen, allows you to customize the following endpoint settings:
- Region: The geographical region where the model is hosted.
- Model: The specific AI model to be used for generating responses.
- Temperature: Controls the randomness of the generated response. Higher values increase the likelihood of more diverse and creative responses, while lower values result in more predictable and deterministic responses.
- Max tokens: The maximum number of tokens (words or characters) that the model will generate in its response.
- Top p: A parameter that controls the sampling of the next token. It represents the cumulative probability of the top tokens to be considered. A higher value means more tokens are considered, resulting in more diverse responses.
- Top k: Similar to Top p, but it directly limits the number of top tokens to be considered when generating the next token.
- Stop: A specific string that, when generated by the model, will cause the response to be truncated.
- Presence penalty: A penalty applied to tokens that have already been used in the response, discouraging the model from repeating them.
- Frequency penalty: A penalty applied to tokens based on their frequency of use in the response, discouraging the model from using the same tokens repeatedly.
- View (UI or API): The interface through which the model will be interacted with. UI refers to a user-friendly graphical interface, while API refers to a programmatic interface accessed via any combination of Python, Javascript, and cURL commands.
- System prompt: A predefined prompt or instruction that is passed to the model along with the user’s input, influencing the tone and direction of the response.
Accessing the Serverless Endpoint Programmatically
As stated above, in addition to the chat UI, you can access the serverless endpoint programmatically using Python, JavaScript, and cURL commands. To get started, switch the configuration toAPI under the View section on the right-hand side of the screen to reveal the relevant code snippets.
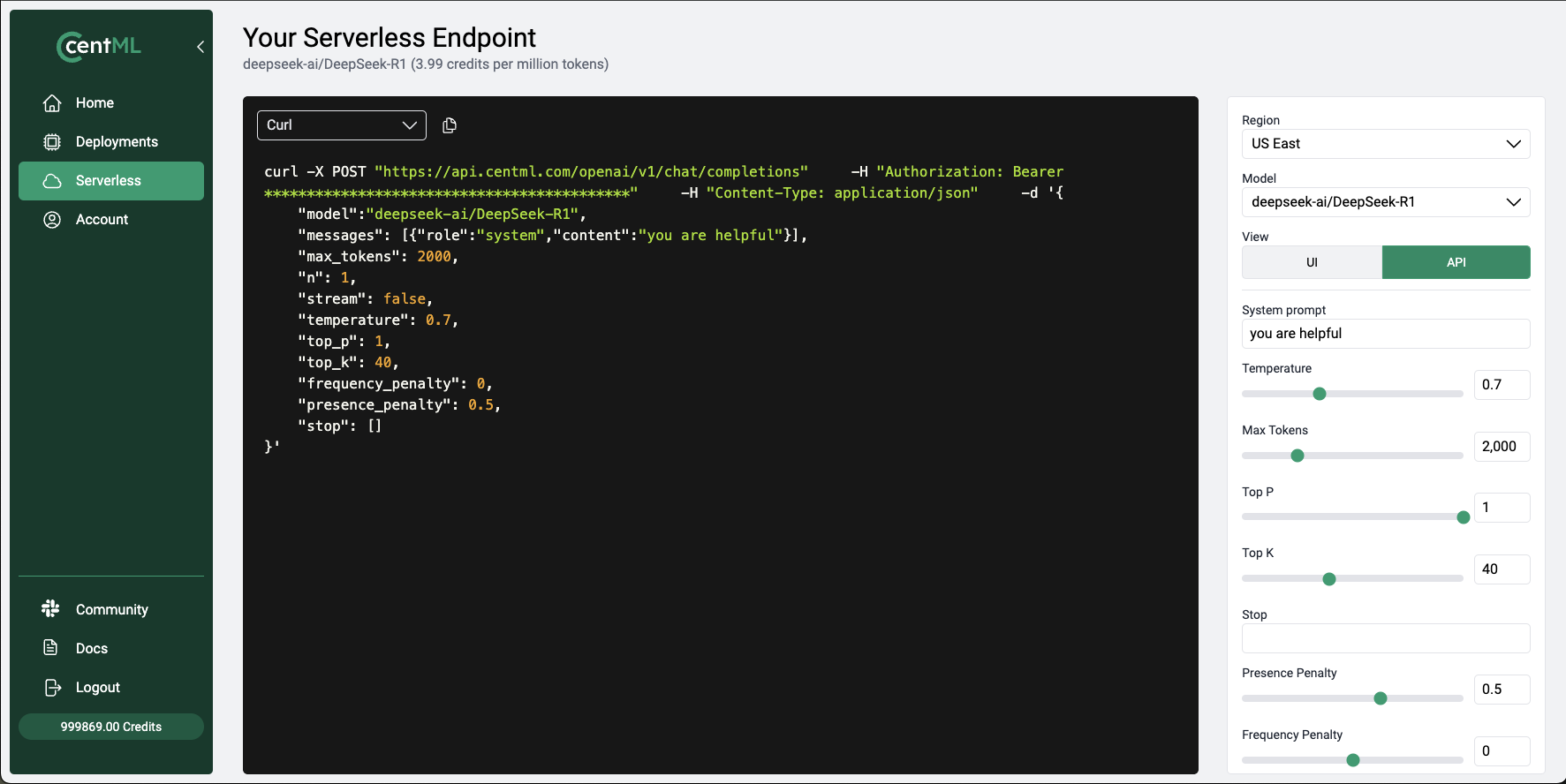
Python, JavaScript, or Curl options to view examples in those respective languages.
Note that the editor is read-only.
To execute the code snippets, you’ll need to run the commands from a separate terminal on a local or remote machine.
The following sections provide example prompts in all supported languages.
Using the Code Snippets (cURL)
To run thecurl commands, copy the platform provided code into your terminal (with cURL installed) and execute it. Note that you must add your API token to the curl command
Example Curl Command

Using the Code Snippets (Python)
In order to execute the Serverless UI provided Python script (should you opt into using Python), you must ensure you install the OpenAPI Python library by runningpip3 install openai from their desired terminal or Python environment.
Once installed, save the Python script from the UI into a file (we named ours centml-serverless.py) and run it using python3 <your file name> (i.e. python3 centml-serverless.py). Note that you will have to ensure you’ve added your API token to the script.
Example Python Script

Using the Code Snippets (JavaScript)
In order to leverage the platform provided JavaScript code snippets, you must install theOpenAI library. You can do so by running npm install openai or yarn add openai in your terminal.
Once the OpenAI library has been installed, save the platform provided code snippet in a file ending with .js. We named ours index.js.
Once you are ready to run the code, run the command node <your file>.js (i.e. node index.js). Note that you will have to ensure you’ve added your API token to the script.
You should see an LLM response!
Example JavaScript Code
Invalid API Key
Should your command return the Invalid API key error, ensure you are using your Serverless API key and not a different key from your vault. It may also make sense to ensure you have the proper syntax. Such as BaseUrl vs. BaseURL.
Data Policies
Prompt Training
Currently CentML does not support prompt training via their Serverless endpoints.Prompt Logging
CentML does not log user prompts when they are submitted to their Serverless endpoints. Refreshing the browser window will reset the model’s memory. During a session, you can view submitted API calls via theAPI option on the right side of the Serverless UI.
This is the same location where example API call snippets are provided.
CentML does not currently provide a way for you to view or extract your chat histories.
Moderation
CentML does not fine-tune or moderate models. However, CentML offers Llama Guard models to help you create a safer experience. Integrating Llama Guard with CentML You can integrate Llama Guard into your chat submission pipelines, utilizing CentML as your inferencing engine and AI infrastructure provider. For optimal performance and guaranteed SLAs, CentML recommends leveraging LLM Serving for such integrations.Additional Considerations When Leveraging CentML’s Serverless Endpoint Offering
Concurrency
When submitting requests to a CentML Serverless endpoint you may witness an{"error":"Concurrent request limit reached, please try again later"}% like message. When using the Chat UI or APIs directly, you are restricted to a limited number of requests based on demand.
CentML Serverless endpoints are multi-user and not a dedicated deployment of a specific LLM nor a production chat application.
CentML serverless endpoints are designed to help you quickly test new models and collect some base performance metrics before moving to a dedicated endpoint such as LLM Serving.
You may choose to use OpenRouter for a higher level of concurrency and guaranteed performance should you not want a dedicated endpoint.
Model Availability
CentML’s Serverless offering only hosts a small subset of the available models out there on the market today. You can submit a request for new models (see below), but should you want to use a fine-tune or domain specific models, then Serverless endpoints are not the optimal solution. You might consider LLM Serving as well as General Inference for more robust use cases.Token Limits
When using the Serverless UI, you may notice a token limit option on the configuration menu on the right side of the screen, that is an artificial limit. Token limits are based on the upstream model limits and not limited when using the Serverless API directly via Python, JavaScript, or cURL commands.Requesting a New Model
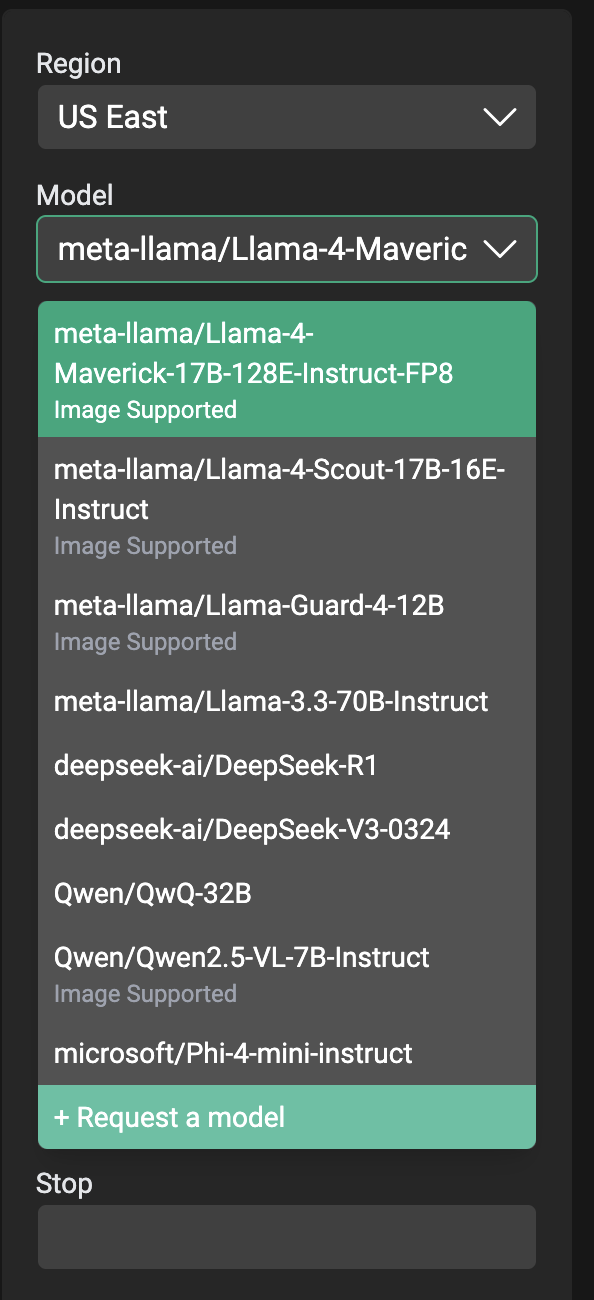
As stated above, CentML does not host every possible (or even popular) model. The team’s goal is to provide models for those looking to begin testing before moving to a dedicated endpoint. Should you want a specific model deployed to the CentML Serverless API/UI, you can request a new model by selecting+ Request a model from the configuration menu on the right side of the screen and filling out the form.
Once submitted, the CentML team will review the submitted request and respond in a timely manner.
Please do not submit multiple tickets with the same model request. That will not expedite the process. Should you need escalation, feel free to reach out to the sales teams you’ve been engaged with or contact sales@centml.ai.
Request a Model
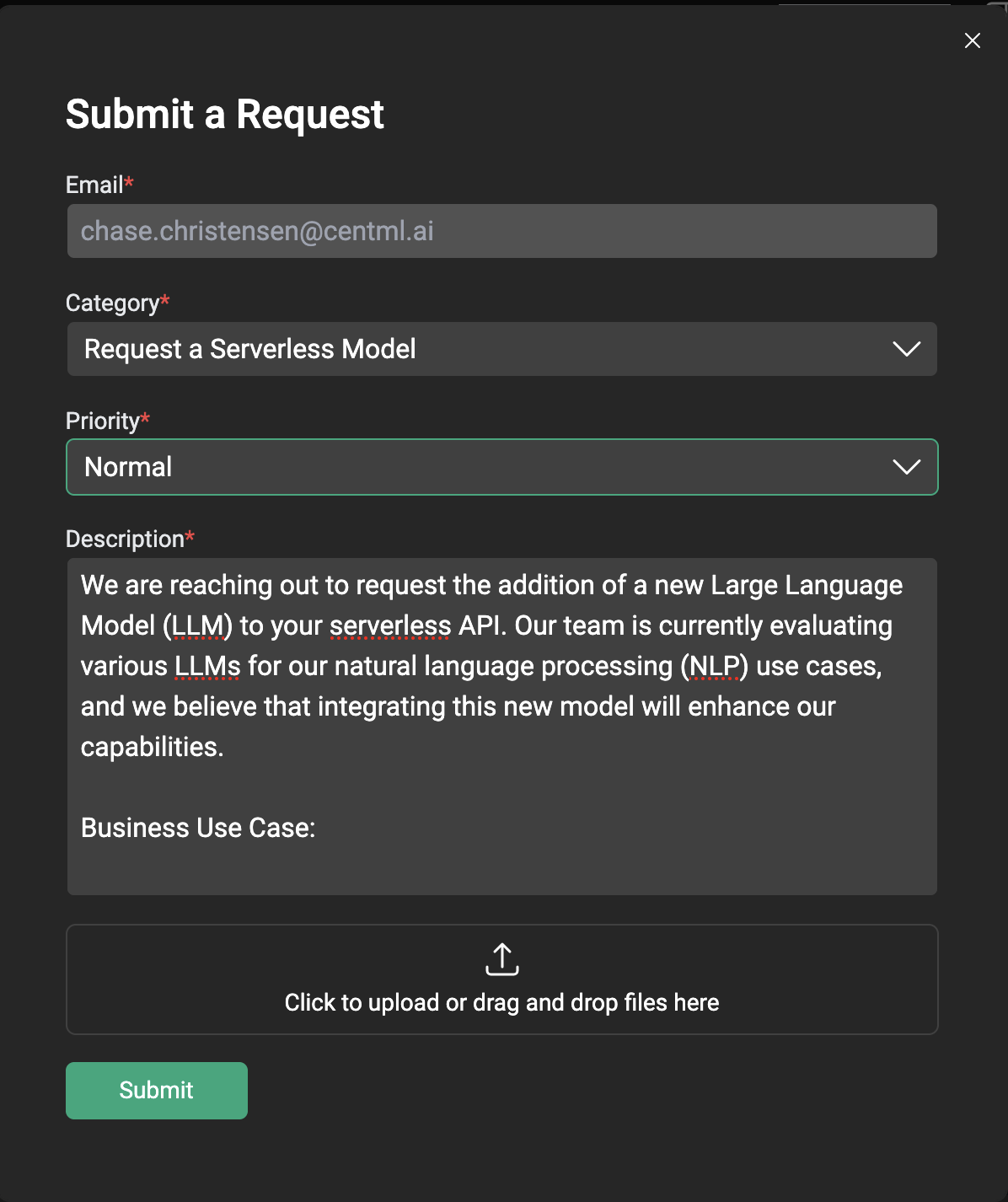
Model Request Ticket Best Practices: What to Include
In the case of a new model addition request, a good support ticket should include:- Use Case Description: A detailed enough explanation of the use case and how it aligns with the business goals.
- Requirements and Constraints: Any specific requirements or constraints related to the request, such as performance, scalability, or security considerations.
- Evaluation Criteria: Information on how the success of the request will be measured or evaluated.
- Current Limitations: Details on how currently available models have failed to meet your requirements.
Example New Model Support Request
Description:
We are reaching out to request the addition of a new Large Language Model (LLM) to your serverless API. Our team is currently evaluating various LLMs for our natural language processing (NLP) use cases, and we believe that integrating this new model will enhance our capabilities. Business Use Case: Our primary use case is to leverage the new LLM for text classification, sentiment analysis, and language translation tasks. We anticipate that this model will provide more accurate results compared to our current models, enabling us to improve our customer experience and gain a competitive edge. Specifically, we plan to use the new model to:Limitations: While the current hosted LLMs show promise, our testing has revealed limitations that impact their suitability for our use cases. Specifically:
- Analyze customer feedback and sentiment on our platform.
- Classify and route customer inquiries to the relevant support teams.
- Translate user-generated content to facilitate global communication.
We’re concerned that these limitations may compromise the accuracy and reliability of our customer-facing applications. We’re looking for alternative models or customizations that can address these issues. Concurrency Considerations: We understand that serverless APIs are designed to handle variable workloads, and we expect our usage to be moderate. Initially, we anticipate an average of 10 requests per minute, with occasional spikes to 50 requests per minute during peak hours. We believe that the serverless API can handle this concurrency level without significant performance degradation. Future Plans: After evaluating the performance of the new model, we anticipate that our usage will grow, and we may eventually require a dedicated endpoint to handle our workload. We are working towards assessing the model’s performance and scalability, and we expect to migrate to a dedicated endpoint if our request volume exceeds 500 requests per minute. We would like to request guidance on the process for migrating to a dedicated endpoint, should it become necessary.
- Lack of domain-specific fine-tuning affects text classification accuracy.
- Sentiment analysis is biased towards certain emotional tones or language styles.
- Language translation struggles with domain-specific content, idioms, and colloquialisms.
CentML Serverless Endpoint Specifications
CentML’s serverless endpoints are OpenAI-compatible endpoints. CentML provides HTTPS servers that implements OpenAI’s Completions and Chat API.| Title | OpenAI-Compatible Endpoint |
|---|---|
| Chat Completions | Post /v1/chat/completions |
| Completions | Post /v1/completions |
https://api.centml.com/openai/v1/ as shown in the examples.
What’s Next
LLM Serving
Explore dedicated public and private endpoints for production model deployments.
Clients
Learn how to interact with the CentML platform programmatically
Resources and Pricing
Learn more about the CentML platform’s pricing.
Deploying Custom Models
Learn how to build your own containerized inference engines and deploy them on the CentML platform.
Submit a Support Request
Submit a Support Request.
Agents on CentML
Learn how agents can interact with CentML services.