General Inference
We make it easy for you to containerize and deploy any custom models on CCluster. Containers can run as any user, including root — see Deploying Custom Models for CCluster security details. We also provide popular inference engine recipes such as vLLM, Ollama, SGLang, and LMDeploy.
1. Configure your inference deployment
Use the Add or Select Image dropdown to choose a pre-configured recipe or manually enter a custom image URL. Similarly, use the Container Tag dropdown to pick an available tag or type one in directly. If you select a recipe, all fields except Add command are auto-filled (some may be empty). You will still need to provide the entrypoint command under Optional Details → Add command.
At a minimum, you need to specify:
- Add or Select Image — the container image URL (select from dropdown or enter manually).
- Container Tag — the image tag (select from dropdown or enter manually).
- Container Port — the port your container exposes its HTTP or gRPC service on.
- Protocol — select
HTTP(default) orgRPC. - Health check path — the endpoint used to verify readiness (e.g.,
/health,/). For gRPC deployments, CCluster uses TCP socket checks automatically, so this field is ignored. - Image Registry Username / Password — required only if the image is hosted on a private registry (e.g., Docker Hub private repo). You can also use credentials stored in your Vault.
Under the Optional Details tab:
- Add command — entrypoint command and arguments. If left empty, the image's default entrypoint is used.
- Autoscaling — set the min and max scale for your deployment. CCluster scales replicas based on max concurrency (maximum in-flight requests per replica). Default is infinity.
- Environment variables — pass additional environment variables to the container (e.g.,
HF_TOKEN).
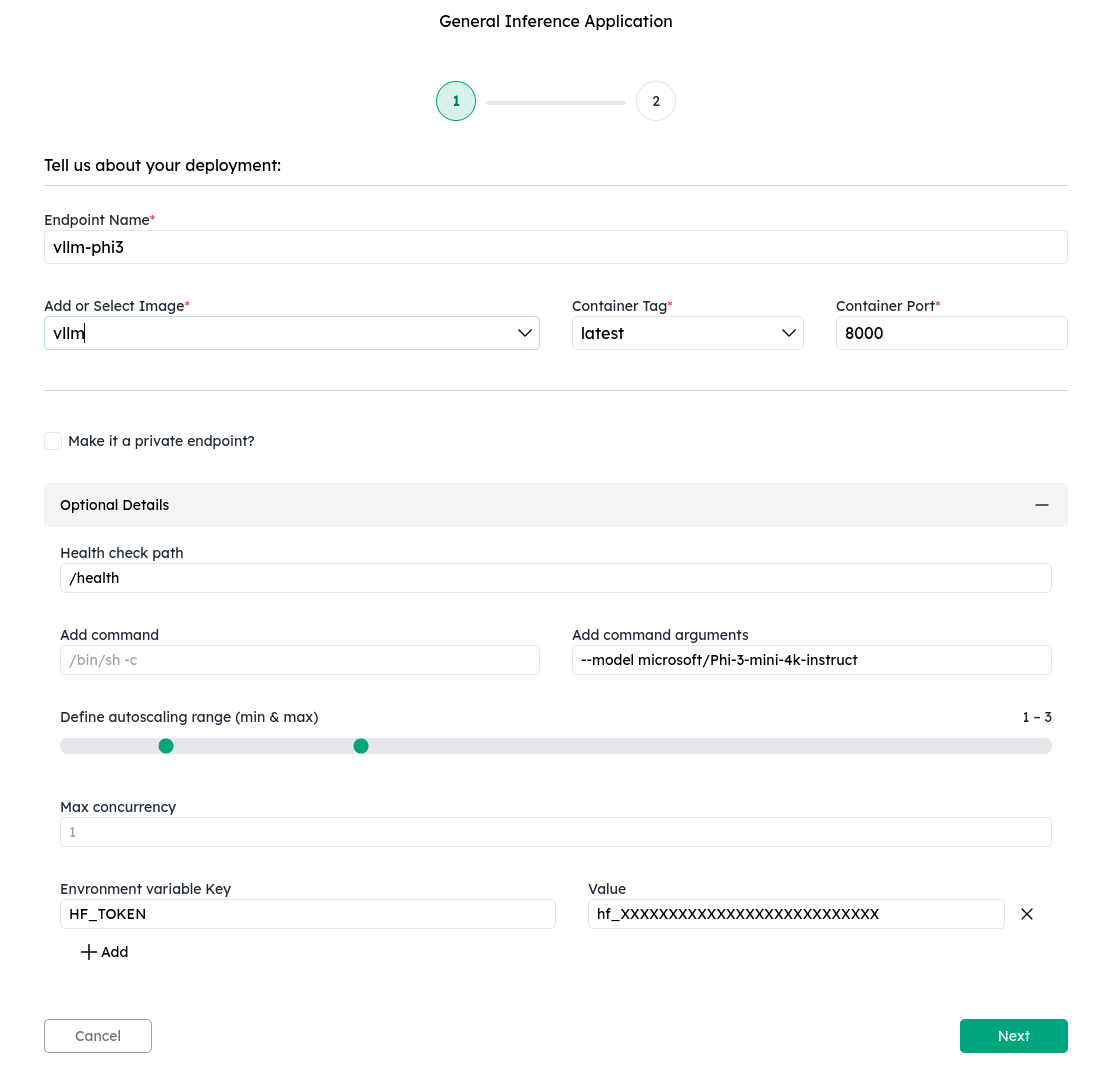
Every deployment must be protected — there are no public endpoints. Secure your endpoint with a Bearer token (an Authorization: Bearer <token> header), an mTLS client certificate, or both. To enable mTLS, select the "Make it a private endpoint?" option, which generates a TLS certificate you can download as a .pem file after the deployment is complete. For more details, see Securing Endpoints.
For building your own custom container image and deploying on NVIDIA CCluster, please refer to this resource.
Protocol: HTTP and gRPC
The Protocol field tells CCluster how your container speaks:
- HTTP (default) — standard request/response over HTTPS. Use this for REST or OpenAI-compatible APIs.
- gRPC — binary RPC over HTTP/2, suited for low-latency or streaming inference. CCluster checks readiness with a TCP socket probe (the Health check path is ignored) and exposes the endpoint as
<endpoint_url>:443with TLS.
For an end-to-end gRPC walkthrough using vLLM's gRPC server, see gRPC Inference Endpoints.
Supported inference engine recipes
CCluster provides pre-configured recipes for popular inference engines in the Add or Select Image dropdown. Selecting a recipe auto-fills all fields except the entrypoint command. Below are the Add command values you need to provide for each engine:
- vLLM —
python3 -m vllm.entrypoints.openai.api_server --model <HF_REPO_NAME> - SGLang —
python3 -m sglang.launch_server --model-path <HF_MODEL_REPO> --host 0.0.0.0 - LMDeploy —
lmdeploy serve api_server <HF_REPO_NAME> --server-name 0.0.0.0 - Ollama — leave Add command empty. See the Ollama-specific note below.
Ollama does not require a custom entrypoint. After the deployment is ready, you need to pull a model before it can serve requests:
# Pull a model (Ollama only)
curl -X POST https://<endpoint_url>/api/pull -d '{"name": "qwen2:1.5b"}'
# Once the pull completes, query the model (Ollama only)
curl -X POST https://<endpoint_url>/api/chat -d '{"model": "qwen2:1.5b", "messages": [{"role": "user", "content": "Hello"}]}'
Deploying NVIDIA NIM containers
NVIDIA NIM microservices are self-contained containers that bundle a model-optimized inference engine and download model weights automatically at startup, exposing an OpenAI-compatible API. NIM is not a pre-configured recipe — enter the image manually.
For the full NIM configuration and an end-to-end walkthrough, see Deploying NVIDIA NIM.
2. Select the cluster and hardware to deploy
By default, NVIDIA CCluster provides several managed clusters and GPU instances for you to deploy your inference containers.
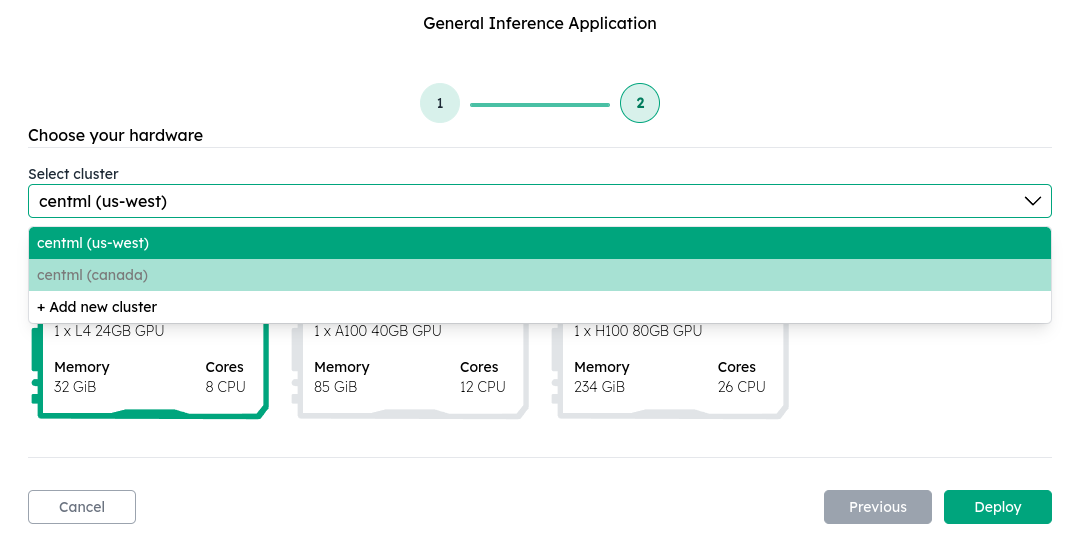
Select the regional cluster and hardware instance that best fits your need and click Deploy.
You can integrate your own private cluster into CCluster through bring-your-own-infrastructure support. To get started, open a support request through your NVIDIA CCluster support channel.
3. Monitor your deployment
Once deployed, you can see all your deployments under the listing view along with their current status.
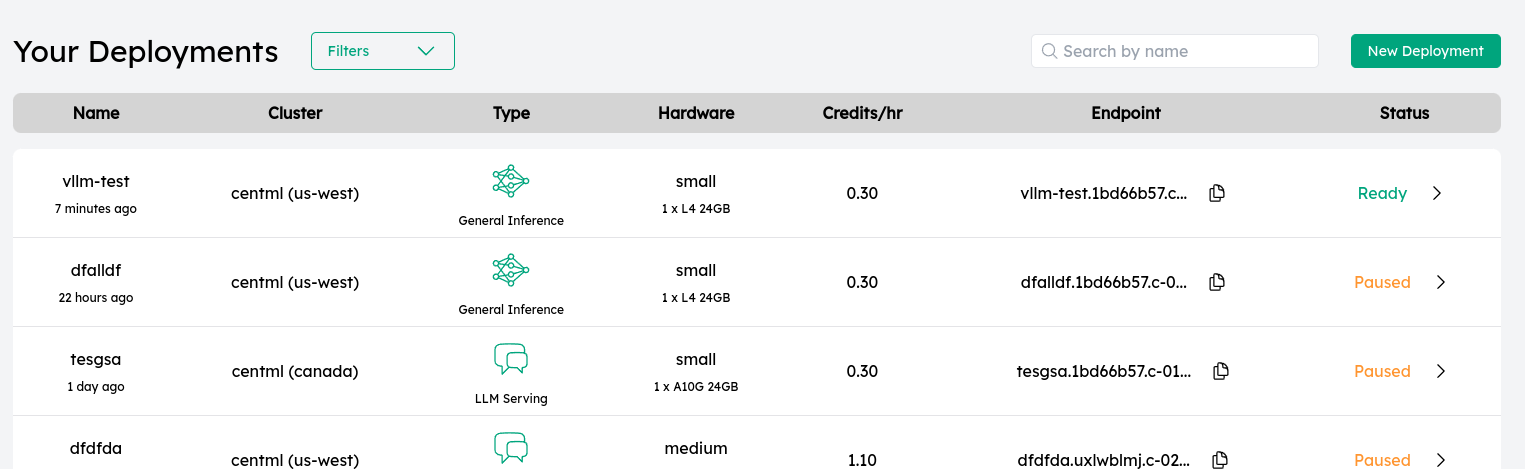
Click on the deployment to view the details page, logs and monitoring information.
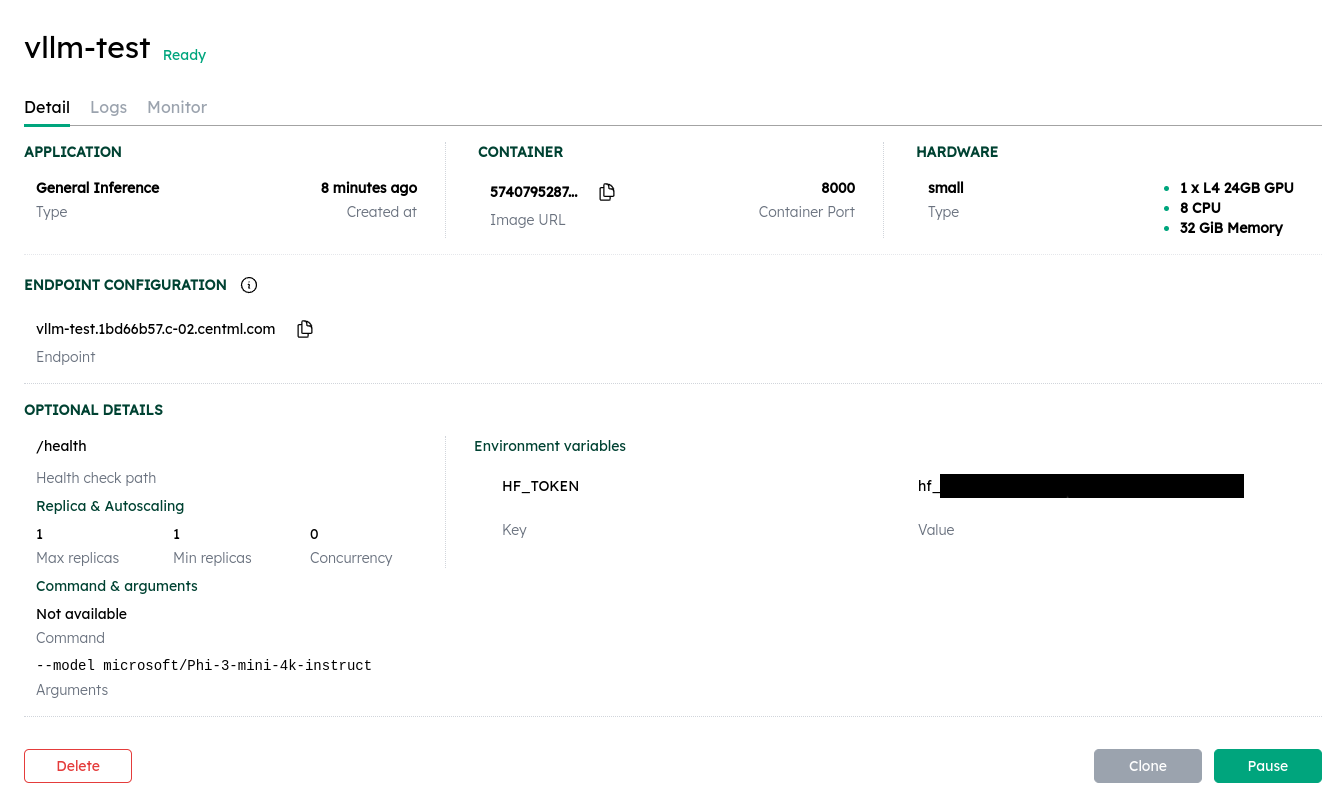
Once the deployment status is ready, the container port is going to be exposed under the endpoint url shown in the details page.
Accessing your endpoint
All deployments are exposed externally on port 443 with TLS enforced. CCluster automatically provisions TLS certificates for your endpoint - no additional configuration is required.
Endpoints are never public: every request must authenticate with a Bearer token or a client certificate. See Securing Endpoints for details.
| Protocol | Access URL | Description |
|---|---|---|
| HTTP | https://<endpoint_url> | Standard HTTPS access (port 443 is implicit) |
| gRPC | <endpoint_url>:443 | gRPC with TLS enabled |
The container port you configure is used internally within the cluster. CCluster's ingress layer handles TLS termination on port 443 and forwards requests to your container's internal port.
Example usage:
# HTTP deployment
curl https://my-deployment.some-hash.cluster-alias.centml.com/v1/models
For gRPC deployments, see gRPC Inference Endpoints for connection and request examples.