LLM Serving
Deploy dedicated LLM endpoints that fits your performance requirements and budget in just three steps.
1. Choose your LLM
Select or enter the Hugging Face model name of your choosing and provide your Hugging Face token. Also provide a name for the dedicated endpoint you are going to deploy.
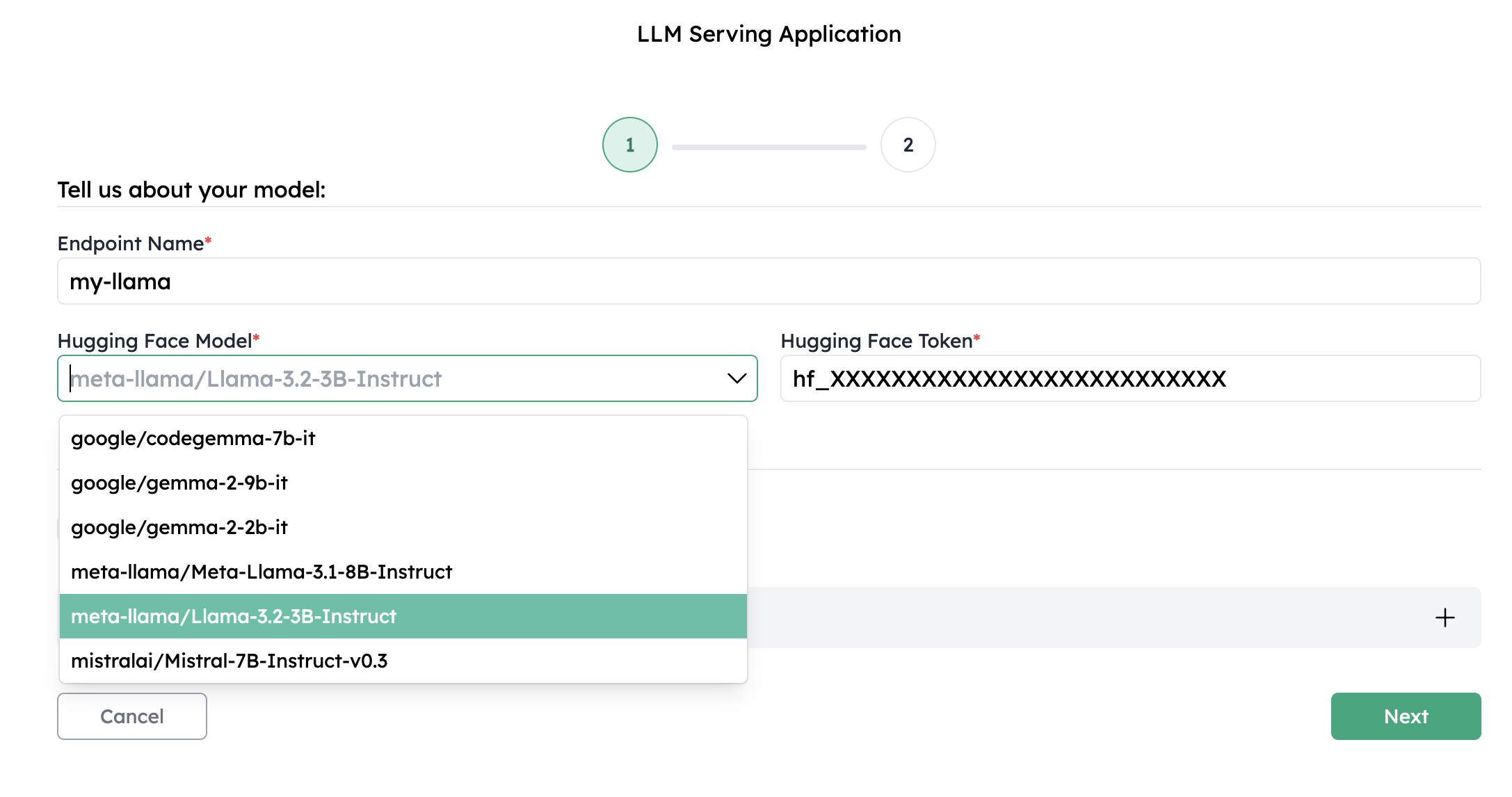
Make sure you have been granted access to the model you selected. If not, please go to https://huggingface.co/ and request for access.
2. Plan and optimize
Choose the cluster or the region you want to deploy the model. Based on that, NVIDIA CCluster presents three pre-configured deployment configurations to suit different requirements:
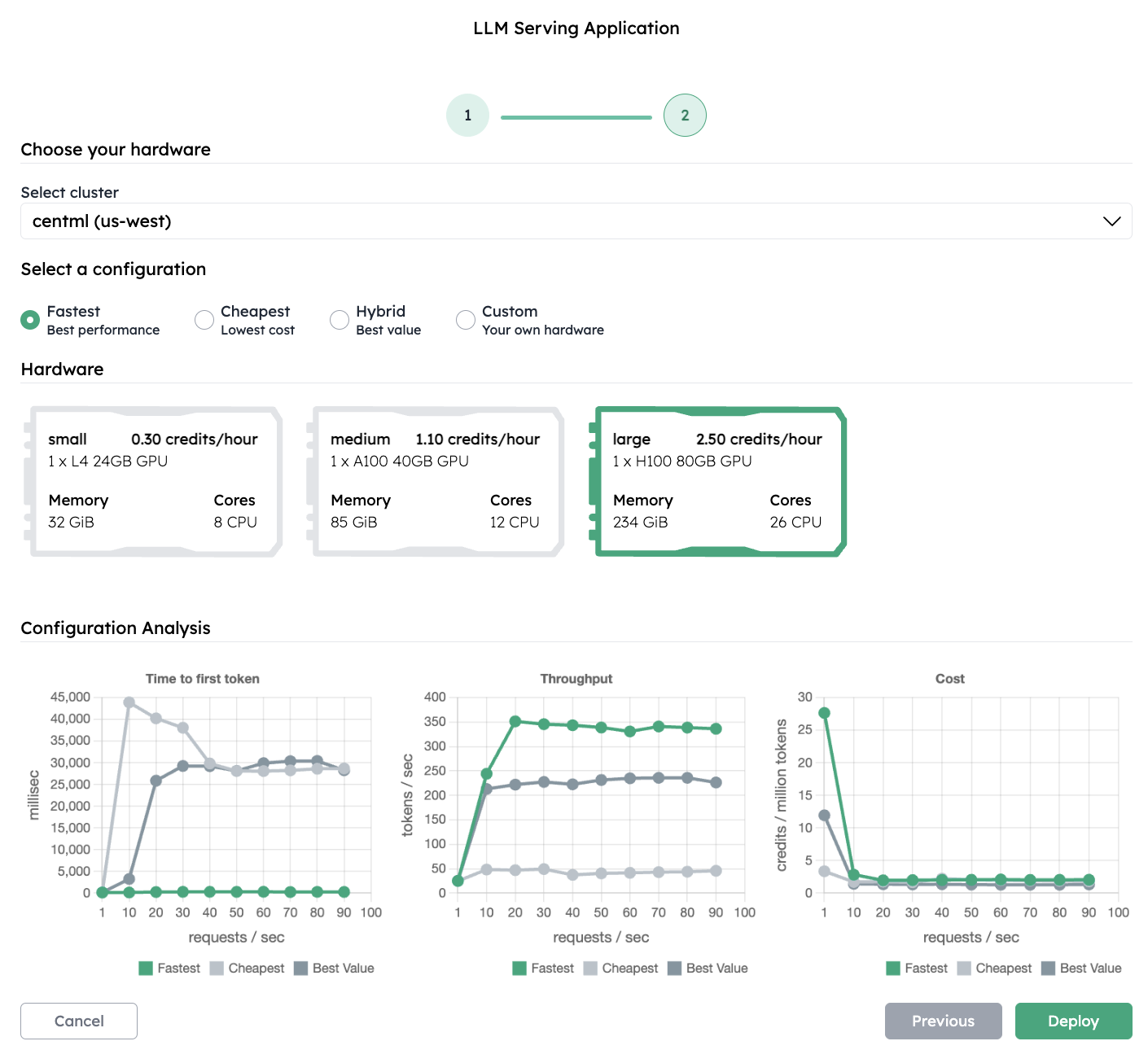
- Best performance: A configuration optimized for latency and throughput, suitable for high-demand applications where performance is critical.
- Lowest cost: A cost-effective configuration designed to minimize expenses, ideal for non-critical applications with lighter usage.
- Best value: A balanced configuration offering a mix of performance and cost efficiency, tailored to provide an ideal trade-off for general usage.
Each configuration is accompanied by detailed analysis on:
- Time to first token: Indicates the latency between sending a request to a language model and receiving the first piece of its response.
- Throughput: Measures the number of requests the model can handle per second.
- Cost per token: Shows the cost of generating a million tokens.
These insights help you choose the configuration that best meets your needs.
(Optional) Performance customization
For advanced users, NVIDIA CCluster also offers an option to customize their model performance configuration. Simply click the "Custom" configuration to gain full control over several tunable parameters.
3. Deploy and integrate
Finally, click "Deploy". Once the deployment is ready in a few minutes, copy the endpoint url and go to https://<endpoint_url>/docs to find the list of API endpoints to start using your LLM deployment. We offer API compatibility with CServe, OpenAI, and Cortex, making integration with other applications seamless.
Endpoints are never public, so every request must authenticate with a Bearer token or a client certificate. The example below uses a Bearer token; see Securing Endpoints for all options.
curl -X 'POST' 'https://<endpoint_url>/openai/v1/chat/completions' \
-H 'Authorization: Bearer <your_bearer_token>' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"messages": [
{
"role": "user",
"content": "what is the meaning of life?"
}
],
"model": "meta-llama/Llama-3.2-3B-Instruct",
"max_tokens": 512,
"n": 1,
"presence_penalty": 0,
"stream": true,
"stream_options": {
"include_usage": true
},
"temperature": 0.7,
"top_p": 1
}'
For more details on how to use the LLM deployment, please refer to the examples we've prepared.