1. Configure your RAG application
Name your RAG application and select the embedding and language models from the drop down list.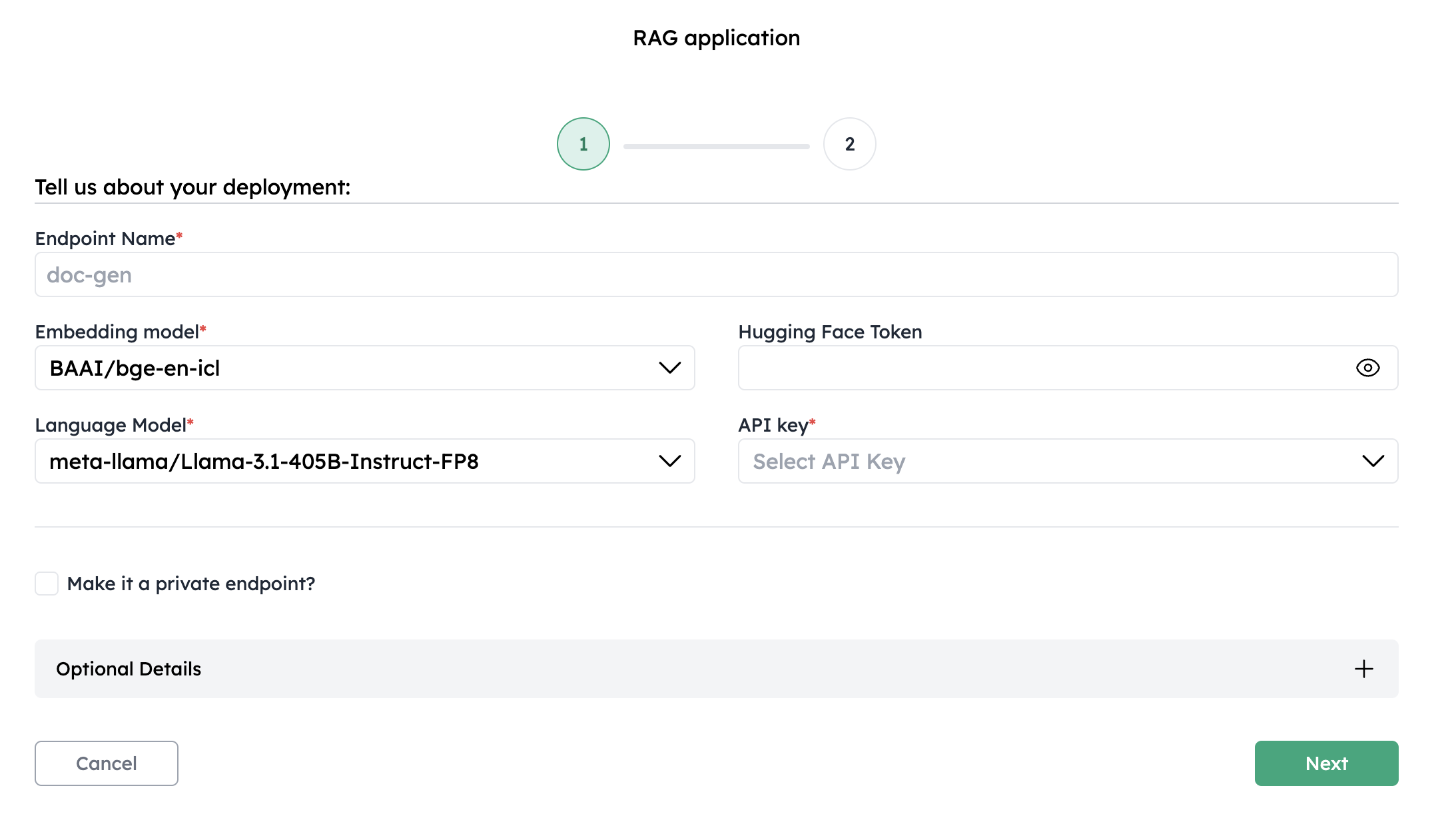
2. Select the cluster and the hardware to deploy
Select the cluster and hardware instance where you want to deploy the embedding model. Click deploy.3. Use the RAG deployment
Once the deployment is ready, go to the Playground tab under deployment details page.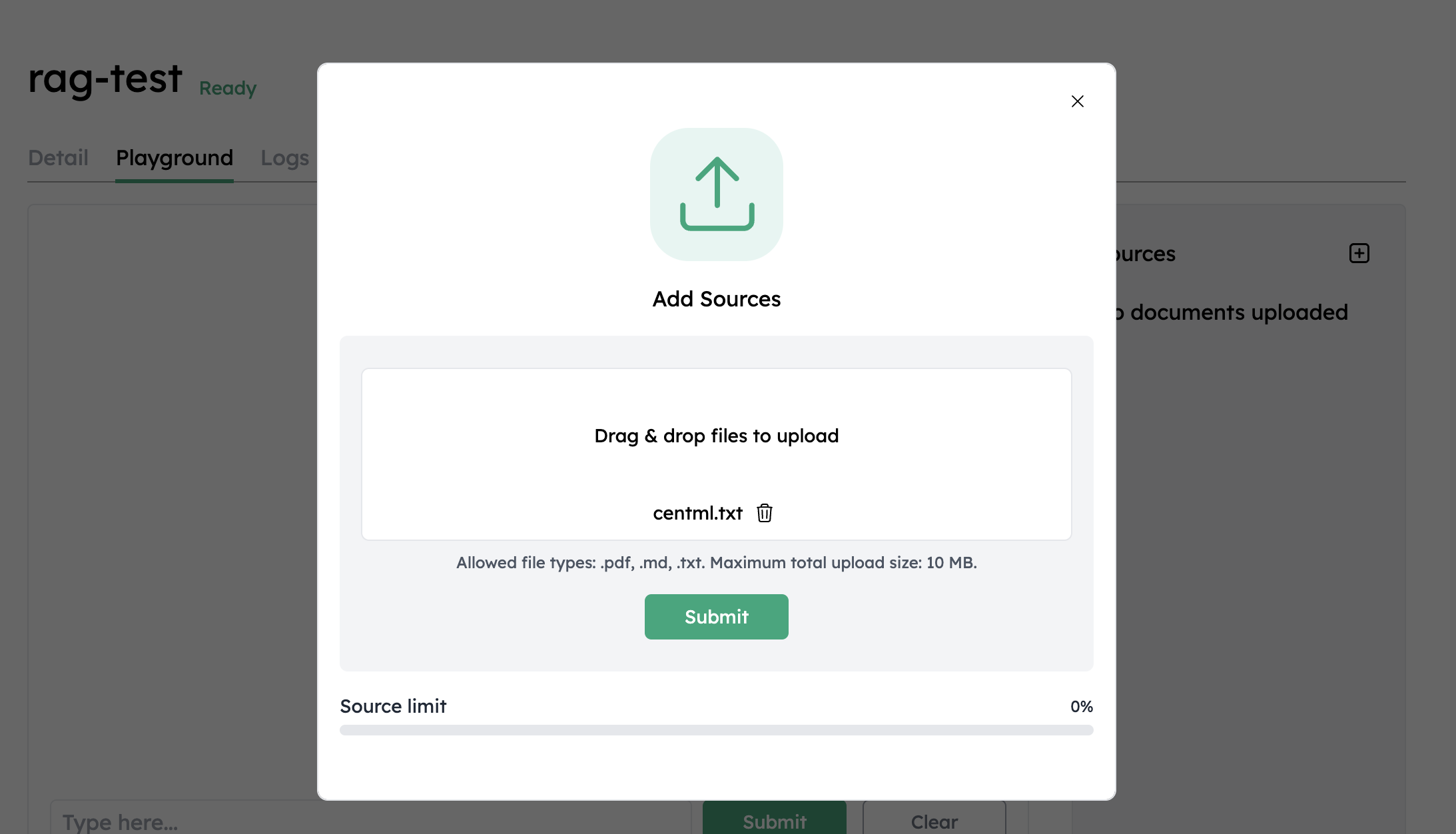
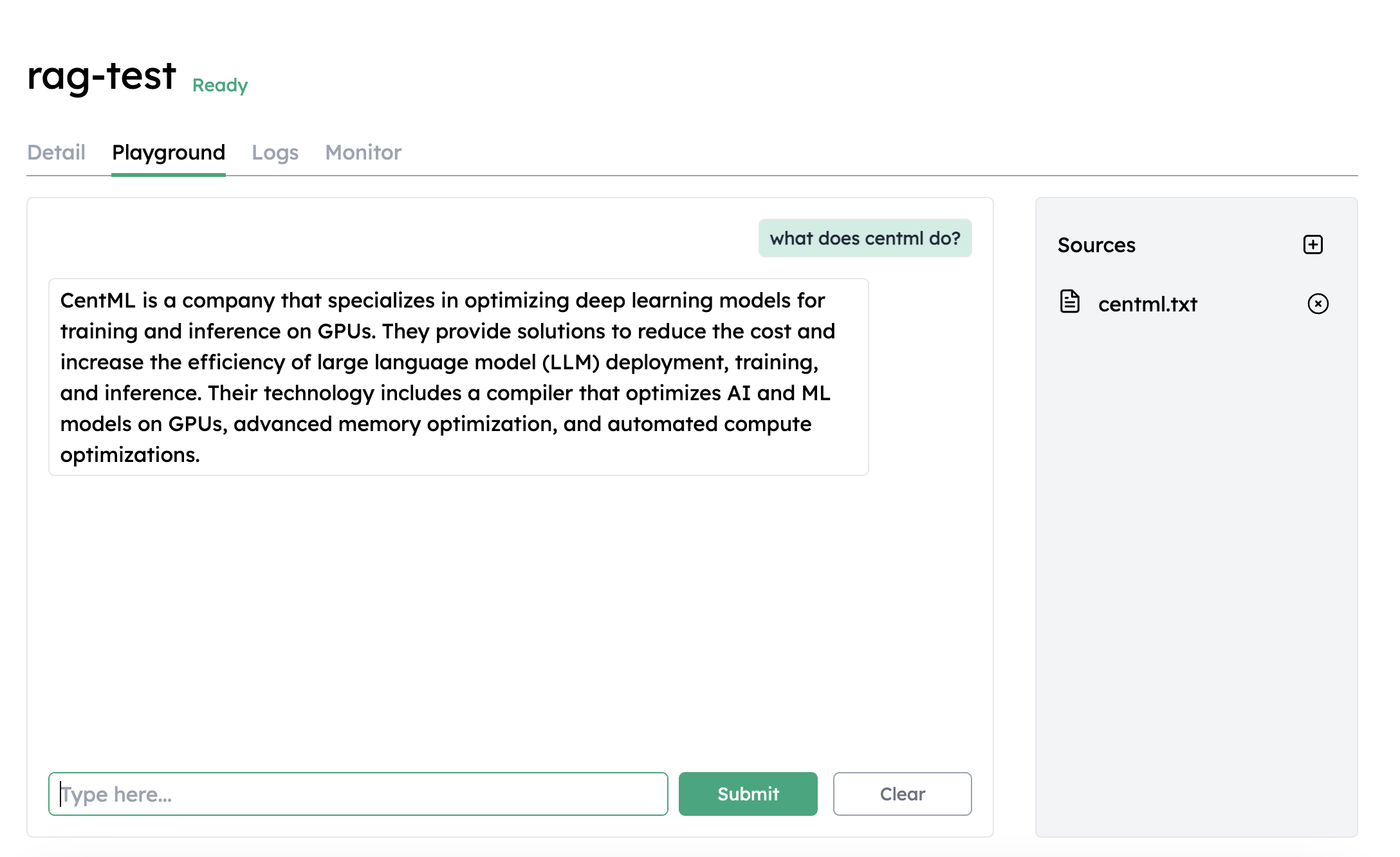
What’s Next
LLM Serving
Explore dedicated public and private endpoints for production model deployments.
Clients
Learn how to interact with the CentML platform programmatically
Resources and Pricing
Learn more about the CentML platform’s pricing.
Private Inference Endpoints
Learn how to create private inference endpoints
Submit a Support Request
Submit a Support Request.
Agents on CentML
Learn how agents can interact with CentML services.